Machine Learning in A/B Testing - Part2
Table of Contents
Experiment and AB Testing Machine Learning Models
Launch an AB Test
We are using an application of A/B testing in marketing in this article.
1. Email AB Test
In marketing, the A/B tests are often done via e-mail with two groups that have different subject lines and they measure the click-through rate to check users’ engagements. In this case, launching A/B testing is simply sending emails to groups and do an analysis on the responses after collecting the data back.
Example service: Campaign Monitor helps businesses with launching e-mail A/B testings.
2. Web Page, Web Application AB Test
In the web page A/B testing case, users in two groups will see two different web pages and we can look at which page has better user engagements.
…
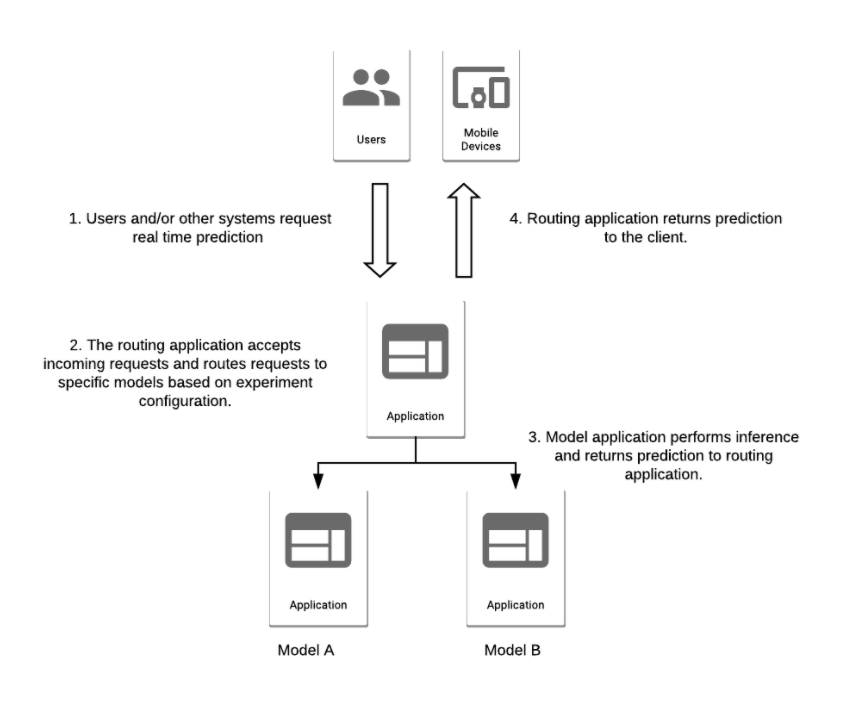 Machine learning model A/B testing architecture. Source: ML in Production
Machine learning model A/B testing architecture. Source: ML in Production
3. About BERT
First of all, when you think about A/B testing, you may want to group your target users based on their web browsing content. A typical example of web browsing data is text, and with conventional natural language processing methods, keyword-based classification models are used. BERT, on the other hand, understands the context of the entire text, and thus is expected to be able to classify users' interests more precisely.
For example, suppose you have a text database of web browsing data of your target users, and you want to divide them into two groups: those interested in machine learning and those interested in software engineering. In that case, we need the text data browsed by users belonging to the two groups for which we know the correct answer, and we can use that data to fine-tune BERT's pre-trained model. Since we do not have such data, in this experiment we will show how to fine-tune BERT using movie review data.
4. BERT Fine-tuning
One of the most common uses of BERT is to download a model that has been pre-trained with a large amount of text and fine tuning it with a small amount of data. In this article, we will show you how to download a pre-trained model from hugginfface and fine tune it with sample code.
- Install Required Packages
pip install datasets
pip install torch
pip install transformers
# When using Google Colab
!pip install datasets
!pip install torch
!pip install transformers
- Load and Check Movie Review Dataset
from datasets import load_dataset
raw_datasets = load_dataset("imdb")
print(raw_datasets)
- Select Samples for Train and Test
sample_train_val = raw_datasets['train'].shuffle().select(range(0,2000)).to_pandas()
sample_test = raw_datasets['test'].shuffle().select(range(0,500)).to_pandas()
- Import Libraries
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score, recall_score
from sklearn.metrics import precision_score, f1_score
from transformers import TrainingArguments, Trainer
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import EarlyStoppingCallback
import torch
import numpy as np
- Define Pretrained Tokenizer and Model
model_name = "bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=2)
- Preprocess Dataset
# Define a simple class inherited from torch dataset
class Dataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels=None):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
if self.labels:
item["labels"] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.encodings["input_ids"])
sample_x = list(sample_train_val["text"])
sample_y = list(sample_train_val["label"])
X_train, X_val, Y_train, Y_val = train_test_split(sample_x, sample_y, test_size=0.2)
X_train_tokenized = tokenizer(X_train, padding=True, truncation=True, max_length=512)
X_val_tokenized = tokenizer(X_val, padding=True, truncation=True, max_length=512)
input_train = Dataset(X_train_tokenized, Y_train)
input_val = Dataset(X_val_tokenized, Y_val)
- Define Evaluation Metrics
def compute_metrics(p):
pred, labels = p
pred = np.argmax(pred, axis=1)
print(classification_report(labels, pred))
accuracy = accuracy_score(y_true=labels, y_pred=pred)
recall = recall_score(y_true=labels, y_pred=pred)
precision = precision_score(y_true=labels, y_pred=pred)
f1 = f1_score(y_true=labels, y_pred=pred)
return {"accuracy": accuracy, "precision": precision, "recall": recall, "f1": f1_score}
- Mount Google Drive (In case of using Google Colab)
from google.colab import drive
# Bert-output is an empty folder in your Drive
drive.mount('/content/gdrive')
%cd /content/gdrive/'My Drive'/'bert-output'
- Fine-tune BERT
# Define Training Arguments
args = TrainingArguments(
output_dir="models",
evaluation_strategy="steps",
eval_steps=100,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=2,
seed=0,
load_best_model_at_end=True,
)
# Define Trainer
trainer = Trainer(
model=model,
args=args,
train_dataset=input_train,
eval_dataset=input_val,
compute_metrics=compute_metrics,
callbacks=[EarlyStoppingCallback(early_stopping_patience=3)],
)
# Fine-tune pre-trained BERT
trainer.train()
- Load Fine-tuned BERT and Run Prediction
# Load test data
X_test = list(sample_test["text"])
X_test_tokenized = tokenizer(X_test, padding=True, truncation=True, max_length=512)
# Create torch dataset
test_dataset = Dataset(X_test_tokenized)
# Load trained model
model_path = "models/checkpoint-100"
model = BertForSequenceClassification.from_pretrained(model_path, num_labels=2)
# Define test trainer
test_trainer = Trainer(model)
# Make prediction
raw_pred, _, _ = test_trainer.predict(test_dataset)
# Preprocess raw predictions
y_pred = np.argmax(raw_pred, axis=1)
Analyze Experimentation and AB Test
With the data that is collected from the activity of users of the website A/B testing or email A/B testing, we can compare the efficacy of the two designs A and B. Simply comparing mean values wouldn’t be very meaningful, as we would fail to assess the statistical significance of our observations.
In order to do that, we will use a two-sample hypothesis test. Our null hypothesis H0 is that the two designs A and B have the same efficacy, i.e. that they produce an equivalent click-through rate, or average revenue per user, etc. The statistical significance is then measured by the p-value, i.e. the probability of observing a discrepancy between our samples at least as strong as the one that we actually observed.
And depending on the metric, we apply different statistical tests.
- Discrete metrics Example discrete metrics: click-through rate
Statistical tests used:
- Fisher’s exact test
- Pearson’s chi-squared test
- Continous metrics
Example continuous metrics: average spending per user, average time spent on a web page
Statistical tests used:
- Z-test
- Student’s t-test
- Welch’s t-test
Conclusion
Machine Learning and Data Science models often can be tricky, there are many things that can mislead you during model development.
- Never trust 100% of the model performance just based on offline testing
- Design your experiment & A/B testing carefully — never miss the minimum required sample size
- When classify users according to their web browsing content (text), BERT can be used
- When training BERT, download the pre-trained model and fine-tune it
- Use statistical tests to compare models performance