RAG with LlamaIndex
📌 Exploring the Integration of Retrieval Augmented Generation with LlamaIndex
What is LlamaIndex?
LlamaIndex is a versatile data framework that enhances the integration of custom data sources with large language models (LLMs), facilitating the development of sophisticated AI applications. It enables developers to ingest various data formats, from APIs and SQL databases to PDFs and presentation slides, into LLM applications.
LlamaIndex not only allows for efficient data indexing and categorization but also provides a robust query interface that generates knowledge-augmented responses. This makes it an invaluable tool for creating applications that perform tasks like document-based Q&A, data-augmented chatbots, and structured analytics through natural language processing.
With features designed for both beginners and advanced users, LlamaIndex offers high-level APIs that simplify the initial steps of data integration and querying, as well as lower-level APIs that give experienced developers the flexibility to customize the framework according to their specific requirements.
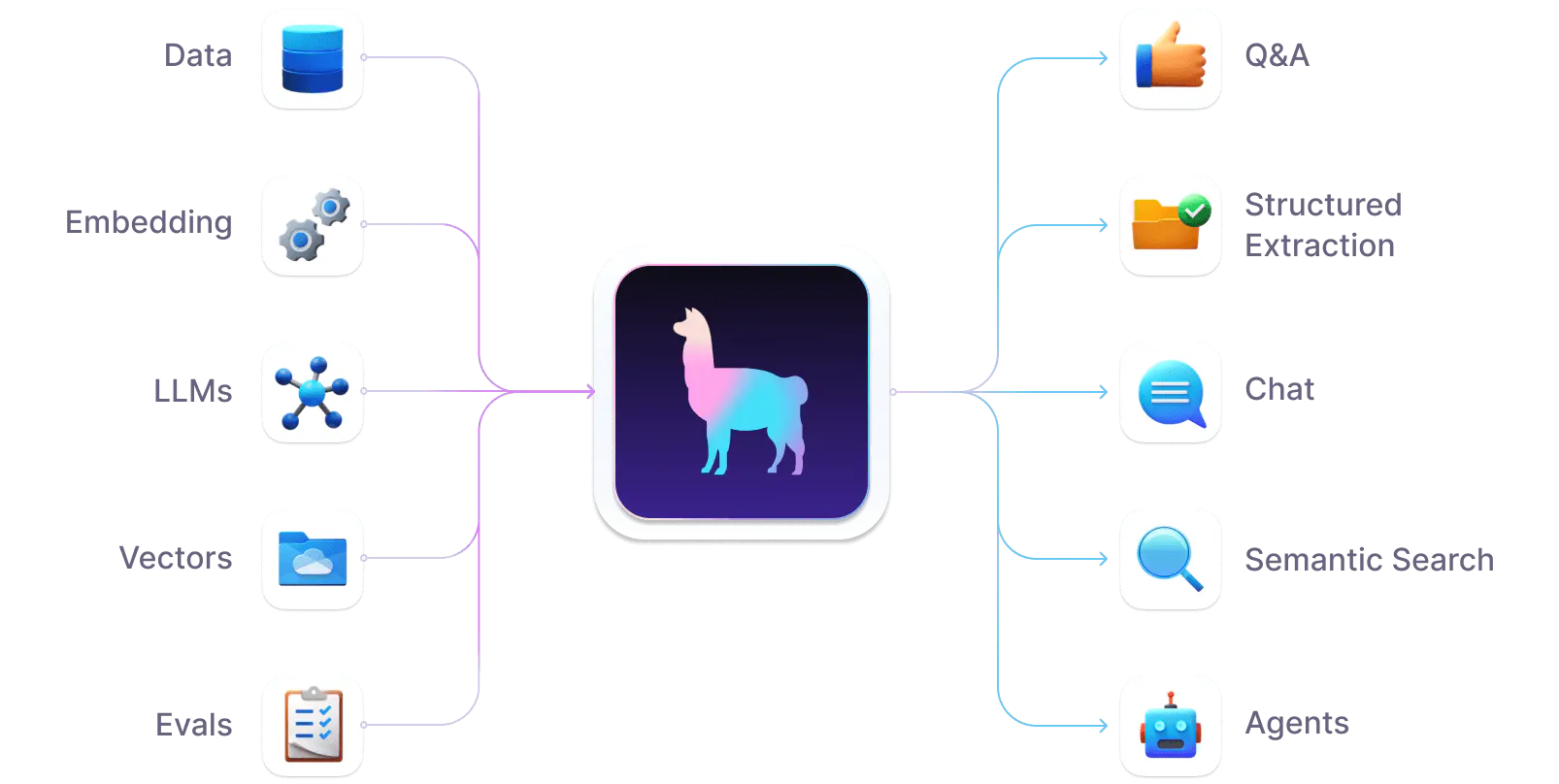 Image source: Turn your enterprise data into production-ready LLM applications
Image source: Turn your enterprise data into production-ready LLM applications
Whether you are a novice looking to explore the capabilities of LLMs or an expert aiming to build complex applications, LlamaIndex provides the necessary tools to create powerful, data-driven AI solutions.
Here are some references to learn more about LlamaIndex:
For further details on how LlamaIndex works and how it can be applied in various projects, you can visit the official LlamaIndex documentation.
 Image source: Turn your enterprise data into production-ready LLM applications
Image source: Turn your enterprise data into production-ready LLM applications
Llama's system comprises three primary components:
- Data Connectors: These facilitate the loading of your data from various sources, including APIs, PDFs, databases, and external applications like Gmail, Notion, and Airtable. You can explore which data sources are compatible by visiting the LlamaHub page here.
- Data Indexers: This component organizes your data and stores it in a format that allows for rapid and efficient retrieval. LlamaIndex offers a range of ready-to-use algorithms for data storage.

 Image source: LLAMAINDEX: AN IMPERATIVE FOR BUILDING CONTEXT-AWARE LLM-BASED APPS
Image source: LLAMAINDEX: AN IMPERATIVE FOR BUILDING CONTEXT-AWARE LLM-BASED APPS - Engines: These act as translators, enabling interactions with the stored data in a conversational, human-like manner.
LlamaIndex vs. Langchain
When evaluating LlamaIndex against Langchain, LlamaIndex is tailored towards the efficient management of large datasets. LlamaIndex streamlines big data processes through:
- Data Ingestion: Integrates data from diverse sources into the LlamaIndex system.
- Data Structuring: Organizes data in formats that language models can easily process.
- Data Retrieval: Rapidly locates data within large datasets efficiently.
- Integration: Enables the merging of your data with vital third-party services.
Conversely, Langchain caters to general applications using large language models (LLMs). Although capable of handling large data volumes, it does not match LlamaIndex in efficiency for such tasks.
Key use cases for LlamaIndex and Langchain:
Langchain
- Text Generation
- Translation
- Question answering
- Summarization
- Classification
LlamaIndex
- Document search and retrieval
- LLM augmentation
- Chatbots and virtual assistants
- Data analytics
- Content generation
This comparison underscores LlamaIndex's focus on data-heavy applications, while Langchain offers broader versatility across various LLM applications.
Merits of LlamaIndex
The advantages of LlamaIndex primarily stem from its features, which are designed to enhance the management and utilization of large data sets in applications that leverage large language models (LLMs). Here are some of the notable merits:
- Scalability and Performance: LlamaIndex allows for the selection of efficient algorithms to store data, which can be tailored for scalability and optimal performance depending on the application needs.
- Diverse Data Connections: The system supports connections to a variety of data sources. Plugins for these data sources are already provided, facilitating easier integration.
- Efficient Data Ingestion: Ingesting data into LlamaIndex is straightforward and fast, reducing the time and complexity typically associated with data integration in large-scale applications.
 Image source: Turn your enterprise data into production-ready LLM applications
Image source: Turn your enterprise data into production-ready LLM applications
Demerits of LlamaIndex
Despite its strengths, LlamaIndex has some limitations:
- Novelty and Adoption: Being relatively new in the market, LlamaIndex is not as widely used as some other established tools. This can mean fewer resources are available for troubleshooting and less community support.
- Limited Documentation and Resources: Due to its novelty, there may be limited documentation and fewer user guides or examples available, which can pose challenges for new users trying to implement the system in their projects.
These pros and cons highlight that while LlamaIndex offers powerful tools for data-driven AI applications, its relatively recent introduction to the market may require potential users to invest in learning and experimentation.
Setting Up LlamaIndex for RAG
To begin using LlamaIndex for a Retrieval Augmented Generation (RAG) setup, start by installing the LlamaIndex package:
Installation:
To install LlamaIndex, use Python's package manager pip. Execute the following command in your terminal:
pip install llama-index
Next, execute the following Python script:
import os
from pathlib import Path
from llama_index.core import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
load_index_from_storage,
)
# check if storage already exists
DATA_DIR = "./data"
PERSIST_DIR = "./storage"
if not os.path.exists(PERSIST_DIR):
# load the documents and create the index
documents = SimpleDirectoryReader(DATA_DIR).load_data()
index = VectorStoreIndex.from_documents(documents)
# store it for later
index.storage_context.persist(persist_dir=PERSIST_DIR)
else:
# load the existing index
storage_context = StorageContext.from_defaults(persist_dir=PERSIST_DIR)
index = load_index_from_storage(storage_context)
def query_data(name):
query_engine = index.as_query_engine()
response = query_engine.query("{name}'s record as dict".format(name=name))
print(response)
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
query_data('Yamada')