RAG with Langchain
📌 Exploring the Integration of Retrieval Augmented Generation with Langchain
Introduction
Retrieval Augmented Generation (RAG) presents an innovative approach to harnessing large language models (LLMs) for generating responses by retrieving relevant information from a dataset. This method circumvents the need for fine-tuning LLMs on private datasets, a process that can be challenging due to privacy concerns, significant computational resources, and time requirements. Additionally, fine-tuning can still result in inaccuracies or hallucinations in the model's output.
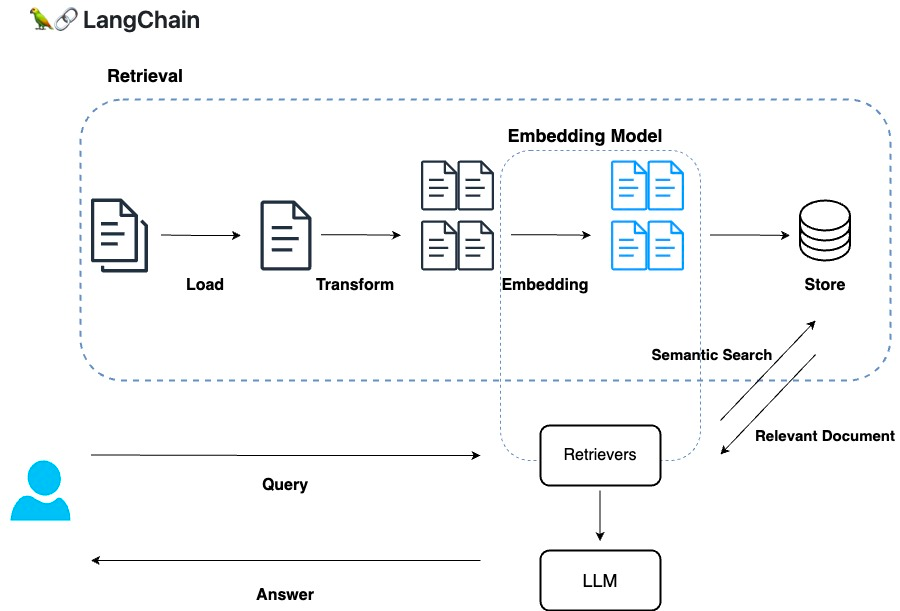 Image source: LangChainとRAG: Embeddingで外部データを利用する
Image source: LangChainとRAG: Embeddingで外部データを利用する
Advantages of RAG over Fine-Tuning
RAG offers several benefits compared to the fine-tuning approach. By feeding correct and specific data into the model's prompts, RAG reduces the likelihood of generating inaccurate responses. Moreover, RAG eliminates the need for extensive training phases, relying instead on a retrieval process to source relevant data for response generation. However, RAG is not without its limitations. Due to constraints on the length of prompts and responses, it may not always be possible to incorporate all relevant data into the model's input, potentially limiting the depth or accuracy of its responses.
Despite these trade-offs, the choice between RAG and fine-tuning depends on the specific requirements and constraints of the application in question. Each method has its unique strengths and weaknesses, making them suitable for different scenarios.
Understanding the RAG process
The RAG process can be broken down into two main components: the background task and the on-the-fly task. In the background task, data is transformed and embedded into a vector format before being stored in a vector database. This preparatory step ensures that data is readily accessible for retrieval.
During the on-the-fly task, when a query is received, the model performs several steps to generate a response. It begins by converting the query into a vector, then retrieves relevant data from the database. This information, along with the original query, is used to construct a prompt that is fed into the LLM, which then generates a response to be delivered to the user.
Langchain: A Framework for LLM Applications
Langchain is a comprehensive framework designed to facilitate the development of applications utilizing LLMs. It offers robust tools and models for integrating different LLMs, managing inputs through prompt engineering, combining LLMs with other components, accessing external data, remembering previous interactions, and overcoming limitations of LLMs by accessing additional tools.
This framework significantly simplifies the process of developing applications that leverage LLMs, providing developers with the necessary resources to efficiently manage conversation history, customize prompts, and integrate various data sources and components. Let's delve into the key components that make Langchain an essential tool for developers working with LLMs.
1. Models: A Gateway to Diverse LLMs and Embedding Models
In the evolving landscape of LLMs and embedding models, selecting the right one for a specific application can be daunting. Langchain simplifies this process by offering interfaces to a wide array of LLMs and embedding models. This flexibility allows developers to experiment with different models, ensuring the best fit for their application's requirements. Whether the task demands nuanced language understanding or specialized knowledge representation, Langchain's versatile model integration capabilities stand ready to meet the challenge.
2. Prompts: Mastering LLM Inputs through Prompt Engineering
The art of crafting effective prompts, or Prompt Engineering, is crucial for eliciting precise responses from LLMs. Langchain acknowledges this by providing a robust set of tools and models that aid in refining prompts. These tools enable developers to adjust and optimize prompts in various ways, ensuring that the LLM can produce the most accurate and relevant answers. This component of Langchain elevates the interaction quality between users and the application, making it a cornerstone of successful LLM application development.
3. Chains: Creating Synergies Between LLMs and Other Components
LLMs, while powerful, are often just one piece of a larger puzzle in application development. Langchain facilitates the integration of LLMs with an array of other components, such as storage solutions, APIs, user interfaces, and more. This integration capability allows for the creation of comprehensive, fully-functional applications that leverage the strengths of LLMs in conjunction with other technological elements, providing a seamless user experience.
4. Indexes: Facilitating Access to External Data
Accessing and retrieving external data efficiently is vital for applications that rely on up-to-date or specific information. Langchain offers mechanisms similar to the background tasks in Retrieval Augmented Generation (RAG) for storing and fetching data from storage solutions. This ensures that applications can access the necessary data promptly and accurately, enhancing the relevance and timeliness of the LLM's responses.
5. Memory: Enhancing Interaction through Conversation History
For applications that mimic human conversation, remembering past interactions is essential. Langchain comes equipped with sophisticated interfaces for managing conversation history, even when dealing with limited token sizes. It allows applications to maintain context over the course of a conversation by storing all dialogues, keeping track of the most recent interactions, or summarizing past conversations. This memory component is crucial for providing a coherent and contextually aware user experience.
6. Agents: Overcoming LLM Limitations with External Tools
LLMs have their limitations, including a lack of contextual information, rapid obsolescence, and difficulties with tasks like mathematics. Langchain introduces the concept of Agents to address these shortcomings. Agents allow applications to access external tools and databases, providing up-to-date information, contextual knowledge not included in the LLM's training data, and specialized computational capabilities. This extends the application's functionality beyond the intrinsic capabilities of the LLM, ensuring a more versatile and reliable user experience.
In conclusion, Langchain stands as a powerful ally for developers venturing into the realm of LLM-based applications. By offering comprehensive support for model integration, prompt engineering, component synergy, data access, conversation memory, and overcoming LLM limitations, Langchain not only simplifies the development process but also opens up new possibilities for innovation and user engagement.
Incorporating RAG into Langchain
Integrating RAG with Langchain offers developers a powerful toolset for building sophisticated applications. Langchain supports essential elements such as selecting appropriate LLMs, embedding and retrieving data, managing dynamic prompts, and processing various types of documents. It also facilitates chunking larger datasets into manageable parts and handling user inputs effectively.
In other words, integrating Retrieval Augmented Generation (RAG) with Langchain efficiently covers all critical aspects:
- LLM Integration: Langchain facilitates easy integration with various Large Language Models (LLMs) like GPT or LLAMA.
- Vector Store: It offers a vector store for efficient storage of data in an embedded form.
- Vector Store Retriever: Langchain includes APIs for the swift retrieval of embedded data relevant to user queries.
- Embedder: It provides embedding tools to transform raw data into vector format for storage and retrieval.
- Dynamic Prompt Management: Langchain enables dynamic adjustment and refinement of prompts for optimal LLM responses.
- Document Loader: The framework supports extracting data from diverse sources and formats for use in RAG applications.
- Document Chunker: Langchain includes tools to segment large datasets into smaller chunks for efficient processing.
- User Input Handling: It processes user queries as the starting point for the RAG workflow, ensuring relevance and responsiveness.
Langchain's Dynamic Prompt Management
A key feature of Langchain is its ability to dynamically manage prompts, allowing developers to tailor the interaction between the user and the LLM. Langchain revolutionizes prompt management by introducing the dynamic PromptTemplate class, moving away from static, hardcoded prompts to a more flexible system that can be customized in real-time. This system divides prompts into four essential segments:
- INSTRUCTION: Serves as a directive to the LLM, outlining the task it needs to perform.
- CONTEXT: Provides background information, guiding the LLM on factors to consider during response generation.
- QUESTION: Poses the query to the LLM, indicating the specific information or response needed.
- ANSWER: Directs the LLM on how to structure its response, tailoring the output to meet specific requirements.
 Image source: Prompt Engineering and LLMs with Langchain
Image source: Prompt Engineering and LLMs with Langchain
To accommodate the varied needs of users and the system, Langchain categorizes prompts into three distinct template classes:
- Human Prompt Class: Designed for direct user interaction, this template captures questions posed by users.
- System Prompt Class: Utilized for augmenting the LLM's context or supplying additional information necessary for generating accurate responses.
- AI Prompt Class: Focused on eliciting responses from the LLM, this template is structured to guide the model in producing answers. Through this structured approach, Langchain not only simplifies prompt management but also enhances the adaptability and precision of LLM responses, catering to a wide range of application needs.
PromptTemplate Class
The foundational class for creating prompt templates is the PromptTemplate class.
# build prompt template for simple question-answering
template = """Question: {question}
Answer: """
prompt = PromptTemplate(template=template, input_variables=["question"])
llm_chain = LLMChain(
prompt=prompt,
llm=davinci
)
question = "Which countries speak Dutch?"
print(llm_chain.run(question))
This basic code snippet doesn't fully showcase the capabilities of Langchain's prompt template.
Exploring FewShotPromptTemplate and LengthBasedExampleSelector:
Utilizing LLMs through few-shot learning involves training them with a minimal number of examples. The FewShotPromptTemplate class demonstrates how this approach is applied:
from langchain import PromptTemplate, FewShotPromptTemplate
# Create examples for few shot
examples = [
{
"query": "How are you?",
"answer": "I can't complain but sometimes I still do."
},
{
"query": "What time is it?",
"answer": "It's time to get a watch."
}
]
# Create example prompt
example_template = """
User: {query}
AI: {answer}
"""
example_prompt = PromptTemplate(
input_variables=["query", "answer"],
template=example_template
)
# Create a prefix and suffix for the prompt
prefix = """The following are excerpts from conversations with an AI
assistant. The assistant is typically sarcastic and witty, producing
creative and funny responses to the users' questions. Here are some
examples: """
suffix = """
User: {query}
AI: """
# Create the FewShotPromptTemplate
few_shot_prompt_template = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
prefix=prefix,
suffix=suffix,
input_variables=["query"],
example_separator="\\\\n\\\\n"
)
To ensure an accurate response from an LLM, it's ideal to supply a multitude of examples. However, given the constraints on prompt size, it becomes necessary to choose examples in a dynamic manner. To facilitate this, Langchain offers the LengthBasedExampleSelector class.
from langchain.prompts.example_selector import LengthBasedExampleSelector
example_selector = LengthBasedExampleSelector(
examples=examples,
example_prompt=example_prompt,
max_length=50 # this sets the max length that examples should be
)
# now create the few shot prompt template
dynamic_prompt_template = FewShotPromptTemplate(
example_selector=example_selector, # use example_selector instead of examples
example_prompt=example_prompt,
prefix=prefix,
suffix=suffix,
input_variables=["query"],
example_separator="\\n"
)
Executing the Code
Below is a straightforward example of how to implement RAG with Langchain. Follow these steps to execute the code:
- Create a Python environment by executing the pipenv command.
- Assign your OpenAI API key to the OPENAI_API_KEY environment variable.
- Execute the script with the pipenv run python main.py command.
# Install python environment
$ pipenv install
# Set the environment variable
$ export OPENAI_API_KEY=your_openai_api_key
# Run the code
$ pipenv run python main.py
This sample code is adapted from: Retrieval Augmented Generation (RAG) Using LangChain
Note: Please ensure that you place the Pipfile provided below into your working directory.
[[source]]
url = "https://pypi.org/simple"
verify_ssl = true
name = "pypi"
[packages]
beautifulsoup4 = "*"
tiktoken = "*"
faiss-cpu = "*"
langchain = "*"
openai = "*"
langchain-cli = "*"
langchain-openai = "*"
jupyter = "*"
[dev-packages]
[requires]
python_version = "3.11"
Conclusion
In conclusion, the integration of Retrieval Augmented Generation with Langchain presents a promising avenue for developing advanced applications that leverage the power of large language models while addressing the challenges of data retrieval, privacy concerns, and computational efficiency.
References
- RAG vs. Fine-tuning: Here’s the Detailed Comparison
- LangChainとRAG: Embeddingで外部データを利用する
- Getting Started with LangChain: A Beginner’s Guide to Building LLM-Powered Applications
- Retrieval Augmented Generation (RAG) Using LangChain
- Building Powerful Language Models with Prompt Engineering and LangChain
- Prompt Engineering and LLMs with Langchain
- Prompt Engineering for LLM Applications with LangChain