Fusing Vector Databases and Large Language Models (LLMs)
📌 Shaping the Future of Data and Natural Language Processing
Introduction
As AI technology evolves, the combination of vector databases and Large Language Models (LLM) is gaining attention. Vector databases, a new type of database, store, manage, and search vector representations (embeddings) of unstructured data, facilitating the transition from keyword to semantic search.
The following image represents a vector database as generated by ChatGPT (DALL-E).

Various vector databases have emerged, enabling multi-lingual and multimodal data processing. These databases efficiently handle massive vector data, achieving scalability and performance. They are capable of a wide range of applications, including unstructured data search (such as images, audio, videos, and text), cluster identification, and recommendation systems.
Recently, they have gained attention for supporting workflows of large language models (LLMs), addressing the demands of AI applications and data processing. This blog delves into how these two powerful technologies are integrated to create new value.
The Depth of Vector Databases
Vector databases store and process complex data such as text, images, and audio in high-dimensional vector form. This enables fast and accurate similarity searches, previously impossible with traditional databases. Key elements of vector databases include:
Optimized Storage
Vector databases efficiently manage large volumes of high-dimensional data, enhancing application performance. These technologies are particularly important as backends for large-scale AI models and data-intensive applications. They distribute data storage and employ techniques like sharding and partitioning to improve scalability and performance.
Distributed Storage
- Sharding: Splits data across multiple servers (nodes), distributing the workload.
- Partitioning: Divides data into smaller, semantically related segments to speed up query performance.
- Replication: Copies data across servers to improve availability and fault tolerance.
Caching Strategies
In-memory Caching: Stores frequently accessed data in fast-accessible memory, reducing database query times.
Data Compression and Optimization
- Data Compression: Saves storage space and optimizes data transfer over networks.
- Data Indexing: Creates indexes for fast data retrieval using techniques like inverted indexes and tree structures.
Benefits of Storage Optimization
Improved Performance: Distributed storage and caching strategies significantly reduce the response time of databases.
Scalability: The system can be expanded in response to increasing data volumes, making it capable of handling large datasets.
Fault Tolerance: Data replication ensures data safety even in the event of system failures.
The figure below represents a vector database as a storage function, and the image is cited from this paper.
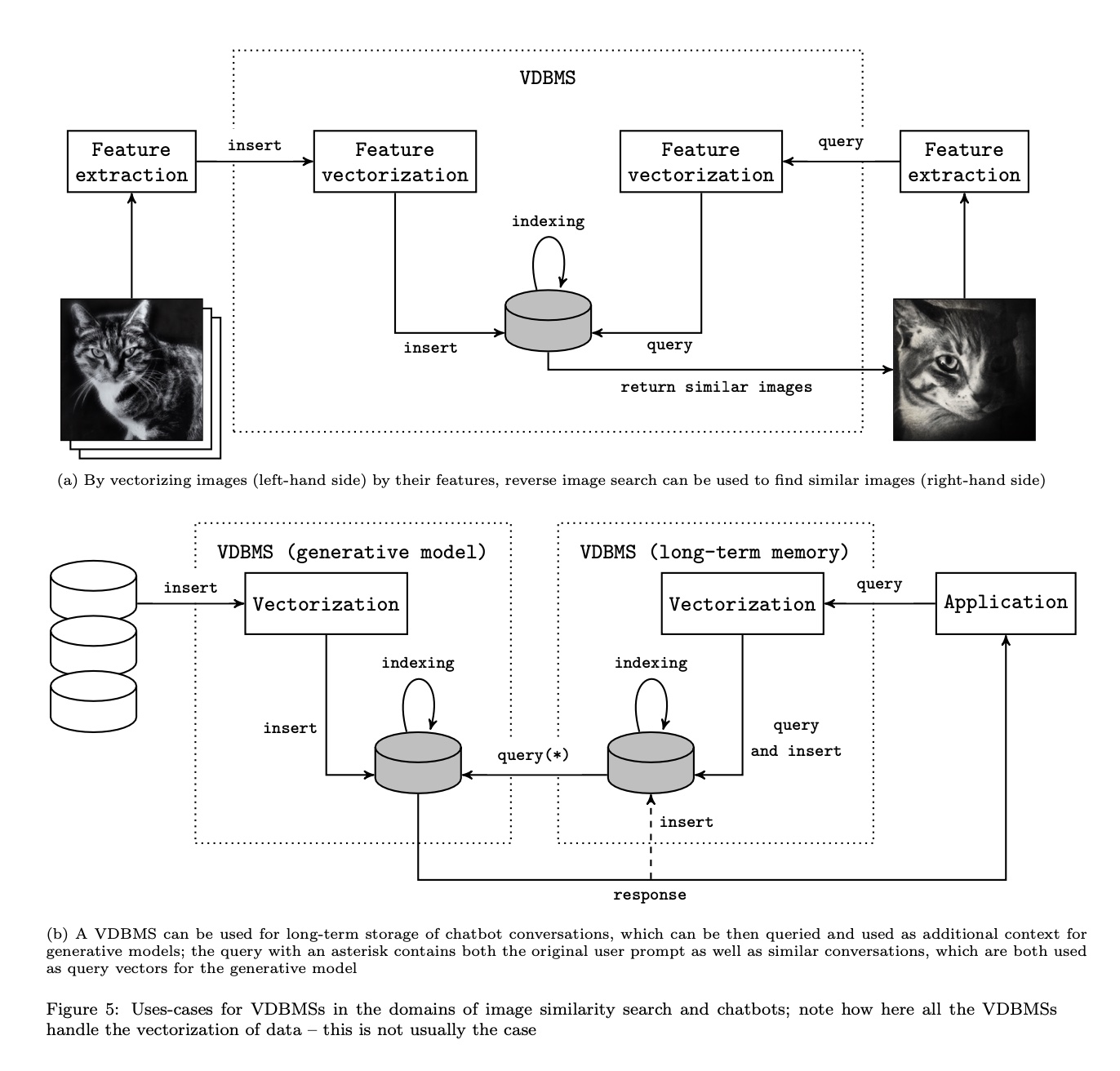
Advanced Search Algorithms
Vector databases employ Nearest Neighbor Search (NNS) and Approximate Nearest Neighbor Search (ANNS) algorithms. NNS provides more accurate results, while ANNS prioritizes faster search and scalability. The choice of algorithm depends on data characteristics and search requirements.
The image below should give you an idea of similarity search. This image is cited from the referenced paper.
Each mechanism has the following characteristics:
Nearest Neighbor Search (NNS)
NNS algorithms use more precise and deterministic methods. These include approaches such as:
k-d Tree (k-dimensional tree): It divides the space one dimension at a time to create regions, used to find the nearest neighboring points to a query. Each node represents a k-dimensional point and serves to divide the space into two half-spaces.
Ball Tree: Encloses groups of points in hyperspheres (balls) and visits only the regions where the nearest neighboring points are likely to be, based on a specific distance criterion. This method is effective for high-dimensional data.
Approximate Nearest Neighbor Search (ANNS)
ANNS algorithms use probabilistic or heuristic methods to provide approximate search results.
Locality-Sensitive Hashing (LSH): Maps similar points to the same or nearby buckets with high probability. Points with the same hash code are likely to be similar.
Best Bin First: Similar to a k-d tree approach but focuses on the most promising bins (regions) to avoid unnecessary comparisons with distant points.
Hierarchical Navigable Small World (HNSW): Utilizes a graph structure, connecting points at different levels of granularity. It finds points closer to the query point by following edges on the graph.
Exploring Large Language Models (LLMs)
LLMs, such as those known in the AI industry through ChatGPT and exemplified by models like GPT-4, have become a focal point of recent discussion. These models, trained on vast text corpora, are capable of understanding and generating natural language almost like humans. This has sparked an exploration into LLMs, reflecting the latest advancements in AI and natural language processing. The features, capabilities, and applications of LLMs are detailed below.
Basics of LLMs
Definition: LLMs are neural network models with billions to trillions of parameters. They learn from large text corpora, grasping complex language patterns.
Learning Process: LLMs are trained through supervised, unsupervised, or semi-supervised learning, utilizing extensive text data (web pages, books, papers, etc.) to learn diverse aspects of language.
Capabilities of LLMs
Natural Language Understanding (NLU): LLMs can understand context, intent, and emotion. They analyze user queries and generate relevant responses.
Natural Language Generation (NLG): They possess advanced text generation capabilities, producing content that matches topics and styles. Uses include story creation, article writing, and automatic summarizing.
Context Awareness: LLMs respond appropriately within the flow of conversation or text, understanding the surrounding context. This enables more realistic, human-like interactions.
Applications of LLMs
Dialogue Systems and Chatbots: They respond in natural language to user questions, facilitating interactive conversations. Used in customer support, education, entertainment, etc.
Content Creation: Generate relevant text based on user-provided prompts. Applied in content marketing, creative writing, academic research, etc.
Language Translation and Multilingual Processing: Facilitate communication across different cultures and languages with their translation capabilities.
LLMs, with their complexity and diversity, revolutionize the field of natural language processing by understanding and mimicking human language. They hold promise in various fields like business, science, and education, and their development and impact continue to attract attention.
Integration of Vector Databases and LLMs
Combining vector databases with LLMs results in applications that leverage the strengths of both data management and natural language processing.
Complementary Functions: Vector databases provide efficient data retrieval, while LLMs offer insights and analyses based on this data.
Real-time Response: LLMs reference information within vector databases to generate appropriate responses instantly to user queries.
By integrating these two capabilities, the following can be achieved:
Semantic Search: When users ask questions in natural language, LLMs analyze the query and retrieve optimal information from vector databases for the response.
Customized Content Creation: LLMs generate personalized content based on user interactions and preferences, efficiently managed by vector databases.
Real-time Knowledge Base Construction: LLMs provide knowledge in real-time based on the latest information and data, answering user queries.
An example of this integration is Retrieval-Augmented Generation (RAG). RAG is a prominent instance of integrating vector databases with LLMs. It extends LLM capabilities with information retrieval systems, giving control over the foundational data used by LLMs when forming responses. With RAG architecture, enterprises can restrict AI-generated content to their vectorized documents, images, audio, videos, etc. LLMs are trained on public data but produce responses augmented by information from retrievers.
The image below is a RAG configuration diagram assembled on Azure, cited from Microsoft Learn.

In RAG integration, vector databases enable AI models to effectively understand and retrieve large datasets, enhancing the AI's ability to generate contextually relevant and accurate responses. Particularly in enterprise applications, the integration of RAG and vector databases holds significant potential for improving AI-driven responses and contextual understanding.
Conclusion
The integration of vector databases and LLMs is a powerful means shaping the future of data science and AI. This fusion anticipates innovative applications across various fields such as business intelligence, customer support, and content generation. The potential of this technological combination in business, scientific research, and the entertainment industry is immense.